
FisFilter_DL_ReadCharacters
| Header: | FIL.h |
|---|---|
| Namespace: | fil |
| Module: | DL_OCR |
Performs optical character recognition using a pretrained deep learning model.
Syntax
void fil::FisFilter_DL_ReadCharacters ( const fil::Image& inImage, ftl::Optional<const fil::Rectangle2D&> inRoi, ftl::Optional<const fil::CoordinateSystem2D&> inRoiAlignment, const fil::ReadCharactersModelId& inModelId, const int inCharHeight, const float inWidthScale, const float inCharSpacing, ftl::Optional<const ftl::String&> inCharRange, const float inMinScore, const float inMinQuality, fil::Polarity::Type inPolarization, const float inContrastThreshold, const bool inCalculateCandidates, const bool inRemoveBoundaryCharacters, ftl::Array<fil::OcrResult>& outCharacters, ftl::Array<ftl::Array<fil::OcrCandidate>>& outCandidates, ftl::Array<fil::Region>& outMasks, ftl::Optional<fil::Rectangle2D&> outAlignedRoi = ftl::NIL, fil::Image& diagInputImage )
Parameters
| Name | Type | Range | Default | Description | |
|---|---|---|---|---|---|
 |
inImage | const Image& | Input image | ||
|
inRoi | Optional<const Rectangle2D&> | NIL | Limits the area where recognized characters are located | |
|
inRoiAlignment | Optional<const CoordinateSystem2D&> | NIL | ||
|
inModelId | const ReadCharactersModelId& | () | Identifier of a Read Characters model | |
|
inCharHeight | const int | 8 - 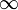 |
35 | Average height of characters in pixels |
|
inWidthScale | const float | 0.1 - 10.0 | 1.0f | Scales image width by the given factor |
|
inCharSpacing | const float | -0.5 - |
0.0f | Distance between characters denoted as fraction of inCharHeight |
|
inCharRange | Optional<const String&> | \"A-Z,a-z,0-9,\\\\\\\\,/,-\" | Limits the set of wanted characters | |
|
inMinScore | const float | 0.0 - 1.0 | 0.5f | Sets a minimum required score for a character to be returned |
|
inMinQuality | const float | 0.0 - 1.0 | 0.0f | Specifies the minimum quality threshold a character must meet to be returned. |
|
inPolarization | Polarity::Type | Any | Sets a required polarity for a character to be returned | |
|
inContrastThreshold | const float | -1.0 - 1.0 | 0.0f | Sets a threshold for a contrast of found characters |
|
inCalculateCandidates | const bool | True | If set to true then outCandidates is calculated | |
|
inRemoveBoundaryCharacters | const bool | False | If set to true characters that are not in full ROI are filtered outconst float inMinQuality, //: Specifies the minimum quality threshold a character must meet to be returned. | |
 |
outCharacters | Array<OcrResult>& | |||
|
outCandidates | Array<Array<OcrCandidate>>& | Array of the most likely characters. The first element is the character from outCharacters | ||
|
outMasks | Array<Region>& | Masks of found characters (in Extended model). Contains empty regions in case of using model not supporting masks (in Fast and Balanced model). | ||
|
outAlignedRoi | Optional<Rectangle2D&> | NIL | Input roi after transformation | |
 |
diagInputImage | Image& | Analyzed area of the input image |
Requirements
For input inImage only pixel formats are supported: 1⨯uint8, 3⨯uint8.
Read more about pixel formats in Image documentation.
Optional Outputs
The computation of following outputs can be switched off by passing value ftl::NIL to these parameters: outAlignedRoi.
Read more about Optional Outputs.
Description
This tool locates and recognizes characters. Without additional training, it is suitable for reading characters:
- horizontally oriented,
- of height between 60% and 140% of inCharHeight (in pixels) - for the FastWide, Balanced, Extended or OcrA models
- of height between 85% and 115% of inCharHeight (in pixels) - for the Fast model
- of height between 45% and 225% of inCharHeight (in pixels) - for the Scalable model
- being latin letters (upper- or lower-case), digits or one of: !#$%&()*+,-./:;<=>?@[]^_`{|}~"'\€£¥.
The pretrained models are described here.
This behavior can be configured with parameters described below.
The inRoi and inRoiAlignment inputs may be used to limit the analysed area, which, in most cases, leads to improved performance. Moreover, it may be used to adjust to text which is not horizontally oriented.
The inCharHeight should be set to the average height of characters (specifically, capital letters) in the analysed area. E.g. if image contains 2 kind of characters: one being 24 pixels high and the second being 40 pixels high, inCharHeight should be set to 32, irrespective of number of characters of each kind. Fast mode supports a more narrow range of character sizes, the character size should be between 30 and 40 pixels.
Here the top row characters are 56 pixels high, whereas the bottom row is 26 pixels. The inCharHeight parameter was set to the average value of 42:
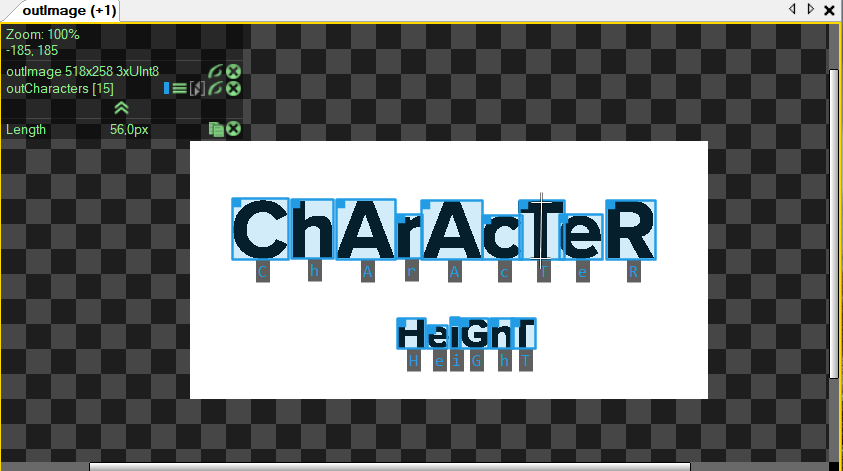
In case of fonts with exceptionally thin or wide symbols, inWidthScale may be used to reshape them to a more "typical" aspect ratio. The analysed area will be scaled by inWidthScale in the horizontal axis. It may improve quality of results. Furthermore, it may also help in reading a text with tight spaces between subsequent characters.
In the image below illustrates how the inWidthScale parameter can be used to read an exceptionally wide font:
To limit the set of recognized characters, inCharRange may be used. This string has to be formatted according to the following rules:
- allowed characters have to be separated with commas,
- for ease of use, continuous range of letters or digits, may be written as starting_character-ending_character, e.g. A-Z or 1-6,
- comma and backslash have to be prepended with backslash.
For example, inCharRange equal to A-F,g-o,0-9,X,Y,Z,-,\\,\, will result in recognizing only ABCDEFXYZghijklmno0123456789-\, characters.
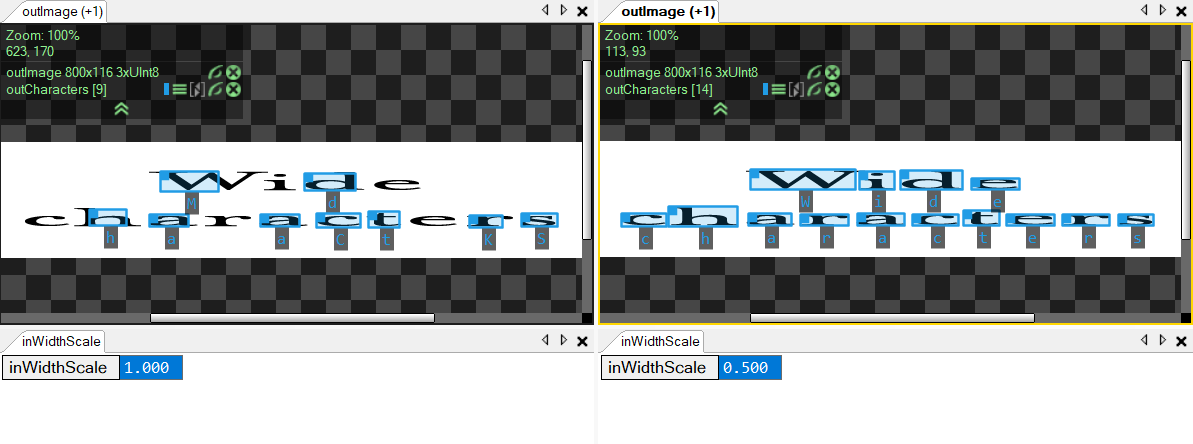
The inMinScore parameter may be used to change minimum score of a character. By default, this threshold is set to 0.5. Changing this parameter, however, may result in showing false characters. See the example image below:
The inContrastThreshold and inPolarization parameters sets a desired contrast interval of a character, which may be used to reduce amount of false positives:
- For inPolarization = Polarity::Bright, only characters with a contrast greater than inContrastThreshold will be returned.
- For inPolarization = Polarity::Dark, only characters with a contrast lower than -inContrastThreshold will be returned.
- For inPolarization = Polarity::Any, only characters with a contrast lower than -inContrastThreshold or greater than inContrastThreshold will be returned.
Example of results with different values of the inPolarization parameter:

Character which is darker than its background have a negative contrast. Opposite situation results in a positive contrast.
Using positive inCharSpacing can eliminate false detections of characters that are close to other characters. Conversely, using negative inCharSpacing can capture more characters that are located near each other. This value is set to 0 by default.
Illustration of outcomes with various values of the inCharSpacing parameter:


To filter out characters that are not fully contained within the Region of Interest (ROI), use parameter inRemoveBoundaryCharacters.
Demonstration of effects using different inRemoveBoundaryCharacters parameter values:


Hints
- It is recommended that the deep learning model is deployed with DL_ReadCharacters_Deploy first and connected through the inModelId input.
- If one decides not to use DL_ReadCharacters_Deploy, then the model will be loaded in the first iteration. It will take up to several seconds.
- In case of characters having too much differing height, it is advised to separate the analysed area (e.g. with inRoi input) to smaller parts containing symbols with a more consistent height.
- In case of poor quality results in Fast mode, check if inCharHeight is set correctly.
- False characters characters can also be removed using MergeCharactersIntoLines.
- To match the known inPattern, use grammar rules in MergeCharactersIntoLines.
Remarks
This filter should not be executed along with running Deep Learning Service as it may result in degraded performance or even out-of-memory errors.
Errors
List of possible exceptions:
| Error type | Description |
|---|---|
| DomainError | Not supported inImage pixel format in FisFilter_DL_ReadCharacters. Supported formats: 1xUInt8, 3xUInt8. |
See Also
- DL_ReadCharacters_Deploy – Loads a deep learning model and prepares its execution on a specific target device.
- DL_LocateText – Performs text detection using a pre-trained deep learning model.
- MergeCharactersIntoLines – Converts a output of Deep Learning filter DL_ReadCharacters to lines of text.